

Focus on Anti-Money Laundering (AML) compliance is gaining prominence given the rising incidences of financial crimes and the innovative ways being used by money launderers to bypass existing checks. At the same time, institutions have struggled with the efficiency and cost of existing processes, which involve high levels of manual and repetitive tasks, that are risk prone in terms of their ability to weed the grain from the chaff.
Artificial intelligence (AI) has been proclaimed as a game changer across disciplines, and AML is no exception. The debate around slow but gradual progress of AI in AML is wide open, with organisations at varying stages of adoption of AI tools and techniques to strengthen their AML programs.
The article initially highlights the value addition that AI can bring within the AML function and how it can transform AML to be more effective, inclusive and risk sensitive. Given the various possibilities, we then look at how different organisations are adapting AI techniques in their AML programs. The last section focuses on two specific use cases for AI and our experience around those.
Artificial Intelligence Based Applications in AML
AI presents a world of opportunities across the business processes involving the compliance function more specifically AML and its sub-disciplines such as Know Your Customer (KYC), Customer Due Diligence and Enhanced Due Diligence (CDD and EDD), and sanctions screening.
Exhibit 1 below discusses the value addition in more detail:

Stages of AI Application in AML
As we have seen above, AI presents many opportunities for making the AML programs more intelligent. However, organisations reside in different stages with respect to the adoption of AI. Many factors affect the adoption, the principal ones being:
- Size and complexity of the organization in terms of type of operations, geographical spread, number of customers and number of transactions
- Understanding of the tools and techniques for AI and availability of the required skill set
- Regulatory guidance and acceptance around usage of AI
- Challenges related to empirical validation of the AI outputs in AML
The above-mentioned factors have led to a maturity spectrum of AI adoption, with the first two stages practically representing zero application of AI – though with increasing data requirement. Stages 2 and 3 use AI in the increasing order of sophistication of techniques.
Details are presented in exhibit 2 below:
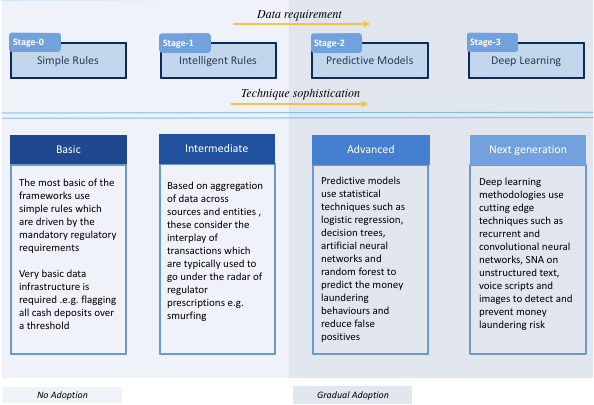
- Simple Rules: The simplest of the rules practically involve no application of AI. More often than not, they are regulatory limits which cannot be exceeded or a very simple transformation of that. Their ability to detect real money laundering activities may be severely limited given that such rules are well understood by the players in the system. From a data standpoint, the rules do not require sifting through complex data patterns. Usage of technology may still be required if there are multitude of transactions across which these rules need to be applied, especially in real time. Some examples are presented below:
- Large daily bi-directional wires with minimum aggregate credit amount exceeding a set threshold and debit amount being 80% of the deposit amount
- An account receiving funds weekly and then rapidly transferring a percentage of those wires in the same week
- Transaction amounts of a customer dominated by round amounts, that is, no cents, tens of dollars, hundreds of dollars, and so on
- Intelligent Rules: These rules consider the ability of the launderers to “structure” the overall transaction in the form of multiple seemingly unrelated transactions, thus needing combination of simple patterns across data sources. Deployment would typically require technology tools to go through volumes of transactions and generate alerts. These however may not look at associations which are triggered by analytical intelligence around past behavioral patterns. Some examples are presented below:
- A customer has excessive transfer activity with unrelated parties
- Rapid Fund movements between charitable organizations and overseas destinations or individuals
- An account’s deposits have been structured across one or more locations in a short time period exceeding the thresholds set for number of locations, number of transactions, and the total deposit amount
- Predictive Models: Predictive models involve usage of established statistical techniques to predict the probability of a customer or a transaction as risky or not from money laundering perspective. The model outputs are used to classify customers or generate rules/ alerts on transactions and categorize them into high, medium and low risk categories. These techniques require significant customer, transactional and behavioral data for analysis and are already being used extensively in the areas of credit risk and customer centricity. Knowledge of data modeling, statistical techniques, AML domain and analytical tools are pre-requisites for their usage as is the requirement for a strong data management platform to produce relevant historical data
- Deep Learning: The most sophisticated of the techniques to be applied go beyond conventional modeling and employ methodologies such as convolutional or recurrent neural networks for analyzing multiple patterns which would be completely obscure to the human eye. They also do not have the limitation of only looking at data in a structured electronic format. Given that usage of informal communication channels is on the rise, analytics on images, unstructured text across native languages, and voice transcripts is applied with specialized algorithms to detect potential money laundering activities. They are typically used in:
- Complex trade transactions across multiple geographies and counterparties
- Detection of money laundering activities conducted through social media platforms involving coded messages, images, voice chats (e.g. for illegal wildlife trade, jewelry transactions, drug pedaling, terrorist financing etc.)
- Approving or blocking of transactions such as credit card transactions, SWIFT messages or customer on-boarding involving unstructured text
- Usage of Natural-language-processing (NLP) to convert data into text and help investigators to write reports and file evidences
The usage of these techniques could be very complex requiring data science experts to perform this job. Further acceptance from regulatory bodies could be difficult as back testing and validations may not be easy to undertake.
Use-cases of AI Application in AML
We now present two use cases based on our recent experience in leveraging AI for AML. Our experience shows that while the adoption is slow, there is enough hope for AI practitioners for usage of stage 3 and stage 4 techniques in the AML space.
The first one is on the usage of predictive models for bringing more efficiency to the investigation process, and the other is on matching accuracy of names and vessels for name and transaction screening focusing on unstructured text mining.
Modelling for reducing false positives:
The model was built for one of the financial institutions based in GCC. The FI had an integration of core banking platforms which led to:
- Data reconciliation issues such as tagging of transactions to the customers. Since the AML system was programmed to flag transactions at a customer level, wherever the tagging was absent, the transactions weren’t picked up by the system. Also, wherever the transaction reference number was having special characters, the transactions weren’t recognized and hence not captured
- The system integration created its own set of organizational challenges. Almost 600-700 alerts were getting generated on a daily basis which the team was finding very difficult to investigate and dispose. This resulted in an accumulated backlog of around 50,000 cases
- The model was built to prioritize the backlog of cases into high risk, medium risk and low risk and hence schedule the investigations based on risk priority and free up capacity of the investigators
The modelling process followed is depicted in exhibit 3 below:
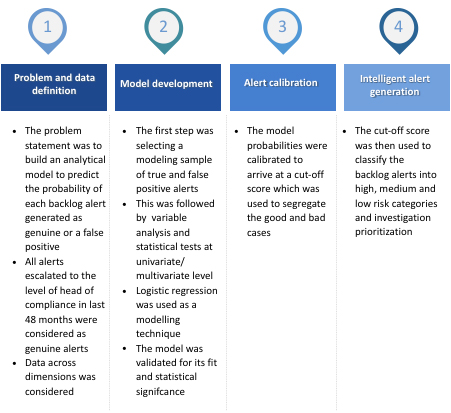
The first step was to define the problem statement and understand the target/dependent variable, i.e. definition of what constitutes a genuine alert and what a false positive is. Data requirements were laid out to build a predictive model. Data dimensions considered are mentioned in exhibit 4 below:
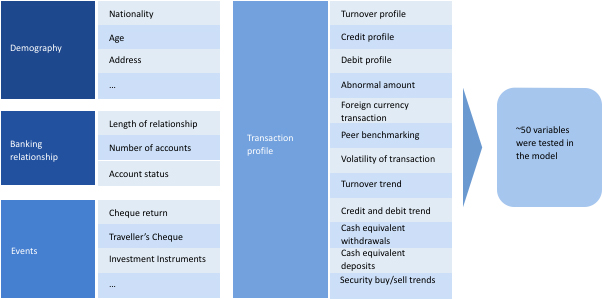
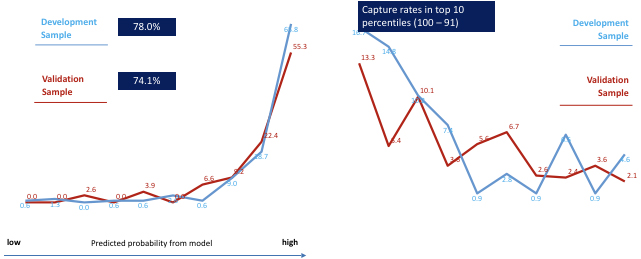
Model was developed using logistic regression (after comparing multiple techniques) which considers a binary state i.e. true alert or a false alert and predicts the probability of an alert being in one of the two states. Robust modelling process was employed and the models were validated with a very high accuracy in both the development and validation samples. The model performance is detailed in exhibit 5 below:
Challenges and learnings:
- The modelling process was a challenging one as the average genuine alerts were around 0.97% of the total cases rendering the training of the model to identify genuinely high risk transactions quite difficult
- Data limitations due to core banking integration also limited the availability and usability of predictor variables
- High performance was achieved through usage of multi-variate patterns and associations that were uncovered through techniques such as principle component analysis
- The model was able to very clearly differentiate the true and false positives:
- A high predictive power ~75% was seen for both the samples
- The institution could capture almost 85% of genuine alerts by focusing on just 30% of the total cases
- The capture rate was very high within the top 3% of cases which could identify ~35% of the true positives leading to immediate prioritization of such cases
- The bottom 30% of the cases had less than 3% of the high-risk cases thus making the model risk efficient
Match algorithms:
This is based on an in-house study commissioned by the team to augment the sanctions screening product developed by our sister company Effiya technologies. Matching is a critical requirement for sanctions screening and could be of two types.
Name matching is required for screening while on boarding a customer, and matching their names against approved lists such as UN list or OFAC or any other regulatory list, to ensure that the person’s name does not figure in the sanctioned list. Matching is also required for screening of transactions to ensure that name of beneficiary or vessel or purpose of transfer etc. is not banned. The payment description could typically be in the form of unstructured text wherein such details may appear anywhere in the narration – with or without spaces. Given that data entry errors may creep in or deliberate attempts to mis-spell words may be made, high match accuracy is an important parameter which will differentiate great technology solutions from the not so good ones.
The team conducted a pilot to assess different algorithms prevalent in the market and tested their performance for match accuracy. The process followed is depicted in exhibit 6 below:
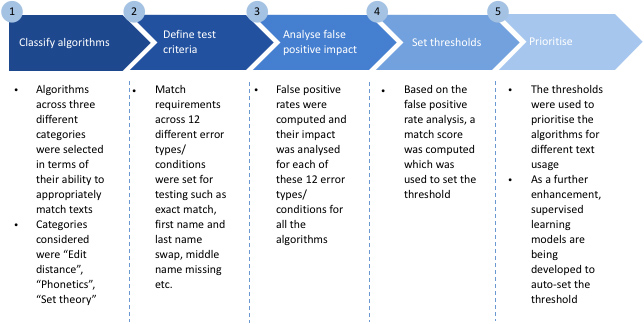
A total of 13 algorithms were selected across three different categories and were used in 12 different match situations. The algorithms tested are mentioned in exhibit 7 below:

The test criteria were matching the various error combinations of the target name, “DENIS MAMADOU GERHARD CUSPERT” against the approved list.
The performance of each of the algorithms was checked on the basis their ability to minimize false positives, based on which thresholds were defined and prioritisation was done for different match situations. The results of the study are mentioned in exhibit 8 below:
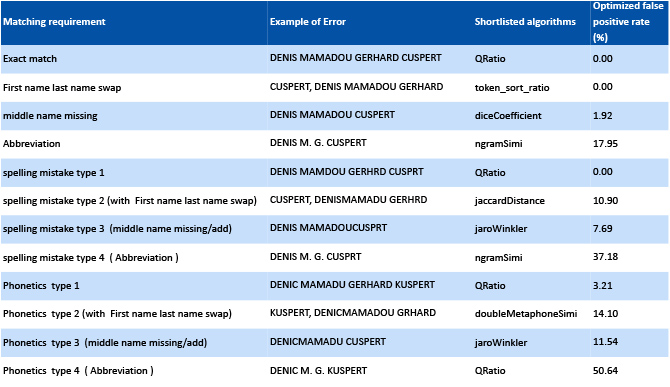
The study has helped to identify the most optimal algorithms for matching specific error combinations. The algorithm combinations have been used in our sanctions product to generate the best match accuracy. As a further enhancement, the algorithms will be put under supervised learning to auto-select the threshold.
Concluding Remarks
Artificial intelligence is an evolving science which has multiple applications. Usage of AI tools and techniques is gradually gaining acceptance, though the final frontier remains unconquered due to many challenges, principal amongst which are data requirements, skill sets and acceptance amongst practitioners and regulators. The best models or algorithms will inherently have a modelling error howsoever small. The cost of allowance for the modelling errors (e.g. a genuine alert getting undetected) will need to be accepted.
Institutions that are considering AI as a strategic priority will reap benefits in the long run as opposed to those who follow a tactical approach. As per experience presented above, efficient use of statistical techniques can definitely augment the capability of the AML function with substantial reduction in the false positive rates. However, a right combination of simple analytical tools, more advanced tools in ML, and understanding of the business and behavioural context is required to harness the true potential of AI.
Authors:
Abhishek Gupta
Managing Director
Email: ag@sutra-management.com
Saurabh Assat
Senior Project Manager
Email: sa@sutra-management.com
Indrani Biswas
Project Manager
Email: ib@sutra-management.com
Sutra Management Consultancies is a group of business advisory firms offering advisory services into Analytics, Business strategy, Financial Crime Compliance and Big data. We use the power of analytics to improve profitability, processes, increase market share of business and make them comply with the regulations. Sutra Management now has 13 years of success serving more than 200+ clients globally and has regional offices in UAE, India and Indonesia.
We are hosting a webinar on changing contours of AML compliance on August 12th 2020, please register for a free participation here.